We will make simple hangman game without graphic of hangman. Program that choose word from list and ask for user input
Done!!!
Full code first_project--HANGMAN.
Happy coding :-)..
- February 15, 2016
- 0 Comments

conda create -n my-r-env -c r r-essentials

| ||
| ##Send a mail to all seller manager and make output for dispatch cockpit | ||
| #delisted file from BI, order from BOB |
| ||
| suppressPackageStartupMessages(require("mailR")) | ||
| suppressPackageStartupMessages(require("lubridate")) | ||
| suppressPackageStartupMessages(require("htmlTable")) | ||
| suppressPackageStartupMessages(require("googlesheets")) | ||
| currentDate = Sys.Date() ##current date to make folder and use in file name |
| #set input to require directory | |
| setwd("M:/R_Script") | |
| filepath=getwd() | |
| setwd(paste(filepath, "Input", sep="/")) |
| seller = read.csv("sellers_delisting.csv", stringsAsFactors = F) | |
| order = read.csv2("order.csv") |
| order_new = order |
| temp = subset(seller, seller$Date.delisted> as.Date(Sys.Date())-30 & | |
| seller$Status =="Delisted", select = c("Seller.Name", "Reason.for.delisting")) | |
| #summarize | |
| seller_delisted = table(temp$Seller.Name.,temp$Reason.for.delisting) |
| ||
| dir.create(as.character(currentDate)) #new folder with name current date | ||
| setwd(paste("M:/Daily/Daily", currentDate, sep="/")) | ||
| csvFileName1 = paste("Threshold limit and seller delisted",currentDate,".csv",sep=" ") #File name with date | ||
| write.csv(seller_delisted, file=csvFileName1, row.names = F) |
| rm(list=ls()) |
| ||
| date = seq(as.Date("2016-01-01"), by = "week", len = 50)) |
|
|
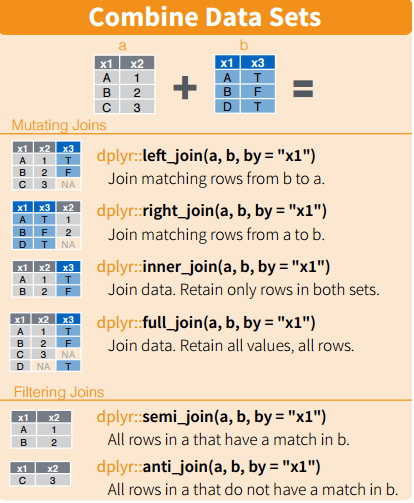
| ||
| or | ||
| id_lookup = right_join(master, id, by="id") ##both column should have common name |
|
| colnames(id)[x] = "id" # x is cloumn index | |
| id_lookup = rename(id, id=id2) # rename is dplyr function |
| ||
| or | ||
| id_lookup = id_lookup[ , c("id", "date") | ||
| or | ||
| id_lookup = id_lookup[,c(1,3)] | ||
| or | ||
| id_lookup = subset(id_lookup, condition, select=c("id", "date")) |
| ###download world bank data "http://data.worldbank.org/products/wdi" #>> "Data catalog downloads (Excel | CSV)">> "CSV" | |
| ##unzip and keep in directory of your choice my is "M:/R_scripts/Combine" | |
| #################load required package | |
| ##if (!require("dplyr")) install.packages('dplyr') # if you are not sure if package is installed | |
| suppressPackageStartupMessages(require("dplyr")) | |
| suppressPackageStartupMessages(require("tidyr")) | |
| suppressPackageStartupMessages(require("reshape2")) | |
| suppressPackageStartupMessages(require("readr")) | |
| suppressPackageStartupMessages(require("googleVis")) | |
| currentDate = Sys.Date() | |
| #########Set the file directory | |
| setwd("M:/") | |
| filepath=getwd() | |
| setwd(paste(filepath, "R_Script/Combine", sep="/")) | |
| #####readfile from your directory | |
| wdi = read_csv("WDI_Data.csv") | |
| country = read_csv("WDI_Country.csv") | |
| i_name= read_csv("WDI_Series.csv") | |
| #### create subset of above data, select only required row | |
| ## required col from wdi | |
| wdi_sub = wdi[ , c(1,3,5:60)] | |
| ##lets run anysis on country name only; #country name in wdi file has other names like summary of region | |
| country_sub = subset(country, country$`Currency Unit`!="" , | |
| select = c("Table Name", "Region")) # if currency unit is blank its not country | |
| colnames(country_sub) <- c("Country Name", "Region") |
| # lets make list of topic | |
| i_name_sub = as.data.frame(table(i_name$Topic)) | |
| i_name_sub = as.character(i_name_sub[,1]) |
| ###let used lappy on each topic lapply(i_name_sub, function(x){ | |
| ## take each list as temp and get Indicator Name related to it | |
| temp = as.character(x) | |
| temp = subset(i_name, i_name$Topic==temp, select="Indicator Name") | |
| ##left join to get only those Indicator data and country | |
| wdi_sub_temp = left_join(country_sub, wdi_sub) | |
| wdi_sub_temp = left_join(temp, wdi_sub_temp) | |
| ##gather date and expand Indicator Name | |
| wdi_sub_temp = gather(wdi_sub_temp, "years", "sample", 4:59) | |
| colnames(wdi_sub_temp) <- c("Indicator.Name", "Country.Name","Region" ,"years", "Value") | |
| wdi_sub_temp = dcast(wdi_sub_temp, Country.Name+years+Region~Indicator.Name, value.var = "Value", na.rm = T ) | |
| ##make years as date | |
| wdi_sub_temp$years = paste(wdi_sub_temp$years,"-01-01", sep="") | |
| wdi_sub_temp$years=as.Date(wdi_sub_temp$years, "%Y-%m-%d") | |
| ##let make unique ID in each dataset if we want to join later on for any analysis | |
| wdi_sub_temp$ID_for_join = paste(wdi_sub_temp$Country.Name, wdi_sub_temp$years, sep="-") | |
| ##save file | |
| setwd(paste(filepath, "R_script/Output", sep="/")) | |
| csvname = paste(gsub(":",",",x),".csv",paste=" ") #file name cant have ":" | |
| write.csv(wdi_sub_temp, file=csvname, row.names = F) | |
| setwd(filepath) | |
| }) | |
| ###total of 91 file will be produced | |
| ###You can find all 91 file #here https://www.dropbox.com/sh/sk7f7uoz9t7mb38/AACxA8gGTXZJV90CycB4uT_Ka?dl=0 | |
| ##download anyfile you need and play around. | |
| #happy coding |
 I'm Bikram -
I'm Bikram -
I'm a Data-holic. I'm passionate about learning new things and playing with data. This blog is a place where I want to share my data analysis tips and tricks, data visualization and automation tips and tricks.
